About me

I am currently a Research Engineer at Adobe Research based in San Jose, California. My interested is in anything related to 3D. For example, I worked on computational optimization of 3D models, and 3D reconstruction of plants for high-throughput phenotyping. I got my PhD at Purdue University, advised by Bedrich Benes. My dissertation was about 3D reconstruction and automatic measurement of sorghum plants. Previously, I completed a double degree at INSA Lyon in France and University of Passau in Germany.


Je suis actuellement ingénieur de recherche pour Adobe Research à San José en Californie. Je m'intéresse à tout ce qui touche à la 3D. Par exemple, j'ai travaillé sur l'optimisation de modèles 3D, et la reconstruction 3D de plantes pour le phénotypage haut-débit. J'ai passé mon doctorat à l'université Purdue, encadré par Bedrich Benes. Le sujet de ma thèse portait sur la reconstruction 3D et la mesure automatique de plantes de sorgho. Auparavant, j'ai été diplômé du département informatique de l'INSA de Lyon et de l'université Passau en Allemagne.
Selected work
Sorghum 3D Reconstruction
Part of my research is about 3D reconstruction and automatic measurements of plants. The image on the right shows a voxel reconstruction of a Sorghum plant imaged at the phenotyping facility of the University of Nebraska-Lincoln. So far, I published a few papers about: 3D reconstruction, skeletonization, segmentation, leaf angle measurements. See the publications page for more details.

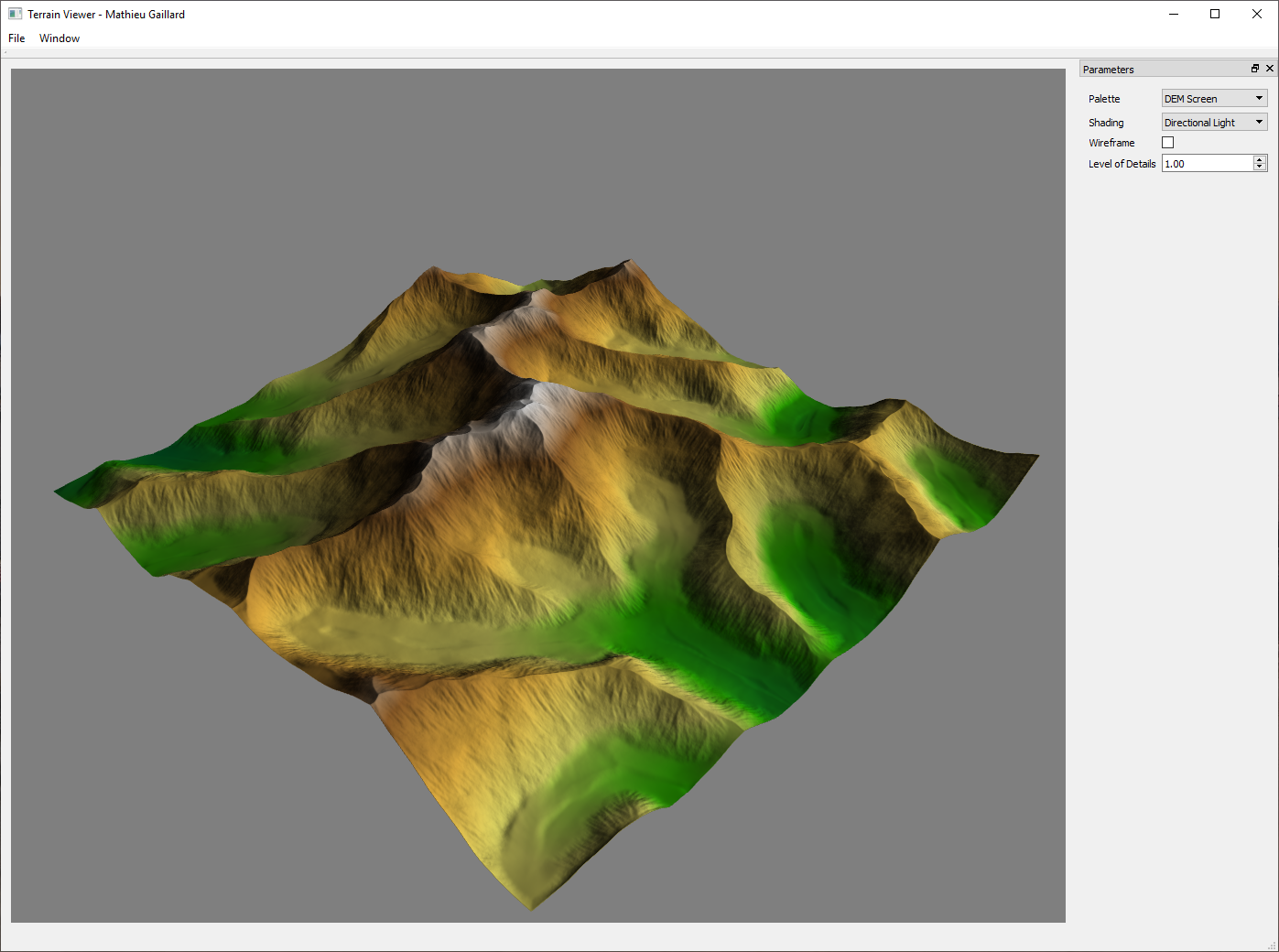
Terrain Viewer Widget
A turnkey Qt Widget to display a terrain in 3D. Tessellation is used to efficiently display the terrain, so that it runs in real time even on low-end hardware. A very efficient algorithm to approximate global illumination has been implemented based on this paper: Timonen, Ville, and Jan Westerholm. "Scalable Height Field Self-Shadowing." Computer Graphics Forum. Vol. 29. No. 2. Oxford, UK: Blackwell Publishing Ltd, 2010.